检索增强生成(RAG)
概述
检索增强生成(RAG)是一种强大的技术,它通过将 语言模型 与外部知识库结合来增强其功能。 RAG 解决了模型的一个关键限制:模型依赖于固定的训练数据集,这可能导致信息过时或不完整。 当收到一个查询时,RAG 系统首先在知识库中搜索相关信息。 然后系统将这些检索到的信息整合到模型的提示中。 模型利用提供的上下文生成对查询的响应。 通过弥合庞大语言模型与动态、针对性信息检索之间的差距,RAG 成为构建更强大、更可靠的 AI 系统的重要技术。
关键概念
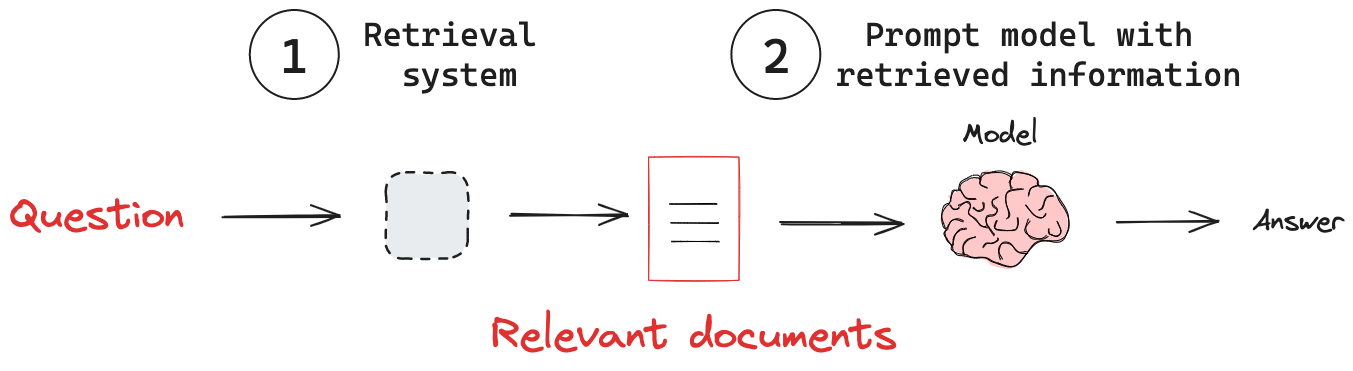
(1) 检索系统:从知识库中检索相关信息。
(2) 添加外部知识:将检索到的信息传递给模型。
检索系统
模型内部的知识通常是固定的,或者至少由于训练成本高昂而很少更新。 这限制了它们回答有关当前事件问题的能力,或提供特定领域知识的能力。 为了解决这个问题,有多种知识注入技术,如 微调 或继续预训练。 这两种方法都 成本高昂,而且通常 不太适合 事实检索。 使用检索系统具有以下优势:
- 最新信息:RAG 可以访问和利用最新数据,使响应保持时效性。
- 领域专业知识:通过特定领域的知识库,RAG 可以提供特定领域的答案。
- 减少幻觉:基于检索到的事实生成响应有助于减少错误或虚构信息。
- 成本效益高的知识整合:RAG 提供了比昂贵的模型微调更高效的替代方案。
请参阅我们的 检索概念指南。
添加外部知识
在具备检索系统之后,我们需要将该系统中的知识传递给模型。 一个 RAG 流水线通常通过以下步骤实现这一点:
- 接收输入查询。
- 使用检索系统根据查询搜索相关信息。
- 将检索到的信息整合到发送给 LLM 的提示中。
- 生成利用检索到的上下文的响应。
例如,以下是一个简单的 RAG 工作流,它将信息从 检索器 传递给 聊天模型:
import { ChatOpenAI } from "@langchain/openai";
// 定义一个系统提示,告诉模型如何使用检索到的上下文
const systemPrompt = `你是一个用于问答任务的助手。
使用以下检索到的上下文信息来回答问题。
如果你不知道答案,就直接说你不知道。
答案最多使用三句话,并保持简洁。
上下文:{context}:`;
// 定义一个问题
const question =
"LLM 驱动的自主代理系统的主要组件是什么?";
// 检索相关文档
const docs = await retriever.invoke(question);
// 将文档内容合并为一个字符串
const docsText = docs.map((d) => d.pageContent).join("");
// 用检索到的上下文填充系统提示
const systemPromptFmt = systemPrompt.replace("{context}", docsText);
// 创建一个模型
const model = new ChatOpenAI({
model: "gpt-4o-mini",
temperature: 0,
});
// 生成响应
const questions = await model.invoke([
{
role: "system",
content: systemPromptFmt,
},
{
role: "user",
content: question,
},
]);