向量存储
为了简化说明,本概述专注于基于文本的索引和检索。 然而,嵌入模型可以是多模态的,向量存储也可以用于存储和检索除文本外的多种数据类型。
概述
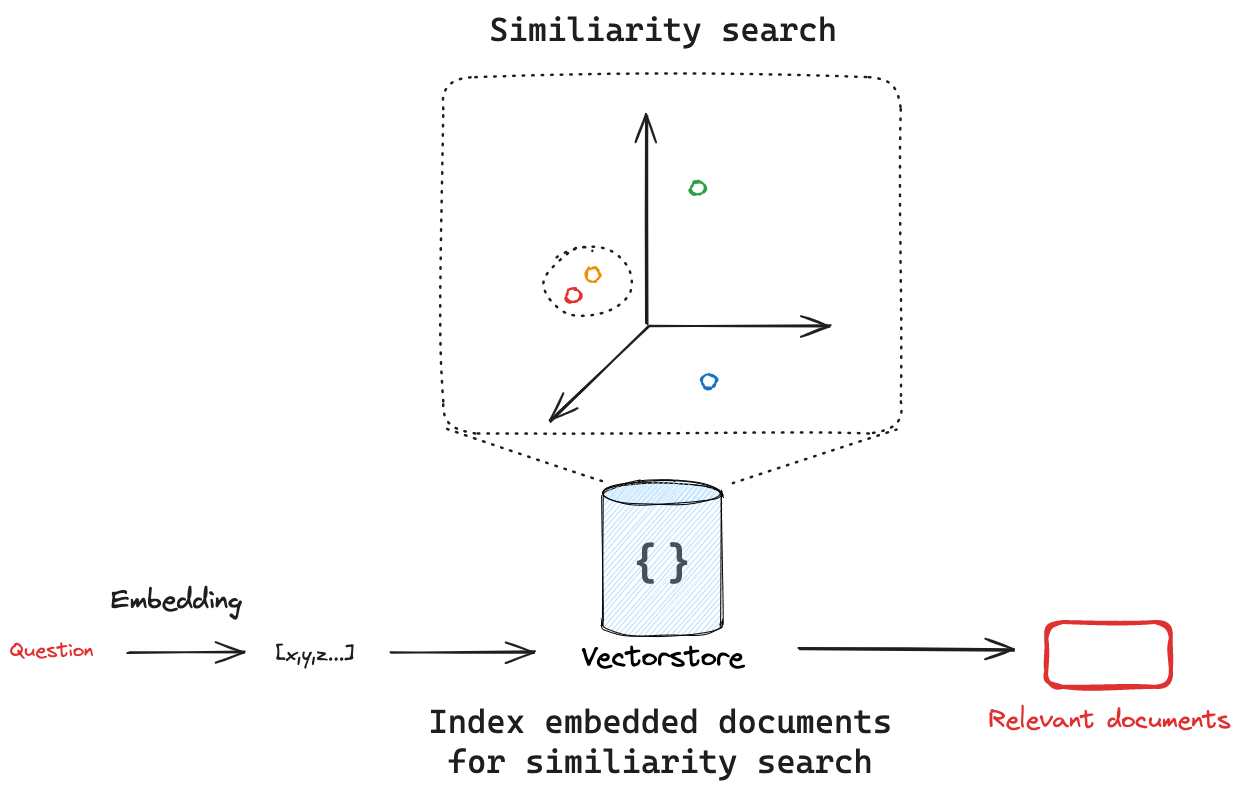
向量存储是一种专门的数据存储,它支持基于向量表示的索引和检索信息。
这些向量称为嵌入,它们捕捉了数据的语义含义。
向量存储常用于搜索非结构化数据(如文本、图像和音频),以根据语义相似性而非精确的关键词匹配来检索相关信息。
集成
LangChain 拥有大量向量存储的集成,允许用户轻松地在不同的向量存储实现之间切换。
接口
LangChain 提供了用于与向量存储交互的标准接口,使用户能够轻松地在不同的向量存储实现之间切换。
该接口包含用于在向量存储中写入、删除和搜索文档的基本方法。
主要方法包括:
addDocuments:将文本列表添加到向量存储。deleteDocuments/delete:从向量存储中删除文档列表。similaritySearch:搜索与给定查询相似的文档。
初始化
LangChain 中的大多数向量存储在初始化时都接受一个嵌入模型作为参数。
我们将使用 LangChain 的 MemoryVectorStore 实现来演示 API。
import { MemoryVectorStore } from "langchain/vectorstores/memory";
// 使用嵌入模型初始化
const vectorStore = new MemoryVectorStore(new SomeEmbeddingModel());
添加文档
要添加文档,请使用 addDocuments 方法。
该 API 与 Document 对象列表一起工作。
Document 对象都有 pageContent 和 metadata 属性,使其成为存储非结构化文本和相关元数据的通用方式。
import { Document } from "@langchain/core/documents";
const document1 = new Document(
pageContent: "今天早上我吃了巧克力松饼和炒鸡蛋。",
metadata: { source: "tweet" },
)
const document2 = new Document(
pageContent: "明天的天气预报是多云和阴天,最高气温62度。",
metadata: { source: "新闻" },
)
const documents = [document1, document2]
await vectorStore.addDocuments(documents)
通常应为添加到向量存储中的文档提供 ID,这样可以避免多次添加相同文档,而是可以更新现有文档。
await vectorStore.addDocuments(documents, { ids: ["doc1", "doc2"] });
删除
要删除文档,请使用 deleteDocuments 方法,该方法接受要删除的文档 ID 列表。
await vectorStore.deleteDocuments(["doc1"]);
或使用 delete 方法:
await vectorStore.deleteDocuments({ ids: ["doc1"] });
搜索
向量存储会嵌入并存储添加的文档。 如果我们传入一个查询,向量存储会嵌入该查询,对嵌入的文档执行相似性搜索,并返回最相似的结果。 这涉及两个重要概念:首先,需要一种方法来衡量查询与任意嵌入文档之间的相似性;其次,需要一种算法来高效地在所有嵌入的文档中执行这种相似性搜索。
相似性指标
嵌入向量的一个关键优势是它们可以使用许多简单的数学运算进行比较:
- 余弦相似性:测量两个向量之间夹角的余弦值。
- 欧几里得距离:测量两点之间的直线距离。
- 点积:测量一个向量在另一个向量上的投影。
在初始化向量存储时,有时可以选择相似性指标。请参考您正在使用的特定向量存储的文档,了解支持哪些相似性指标。
相似性搜索
给定一个用于衡量嵌入查询与任何嵌入文档之间距离的相似性指标后,我们需要一种算法来高效地在所有嵌入的文档中搜索以找到最相似的文档。
实现这一目标的方法有多种。例如,许多向量存储实现了 HNSW(分层可导航小世界),这是一种基于图的索引结构,支持高效的相似性搜索。
无论底层使用何种搜索算法,LangChain 的向量存储接口对所有集成都提供了 similaritySearch 方法。
这将接受搜索查询,创建嵌入,查找相似文档,并将它们作为 Document 列表返回。
const query = "我的查询";
const docs = await vectorstore.similaritySearch(query);
许多向量存储支持通过 similaritySearch 方法传递搜索参数。请参阅您正在使用的特定向量存储的文档,了解支持哪些参数。
例如,Pinecone 支持一些重要的通用参数:
许多向量存储支持 k 参数,用于控制返回的文档数量,以及 filter 参数,允许根据元数据过滤文档。
query (string) – 用于查找相似文档的文本。k (number) – 要返回的文档数量,默认为4。filter (Record<string, any> | undefined) – 用于元数据过滤的参数对象
元数据过滤
虽然向量存储实现了一种搜索算法,用于在所有嵌入的文档中高效搜索以找到最相似的文档,但许多向量存储还支持元数据过滤。 这允许通过结构化过滤来缩小相似性搜索的空间。这两个概念很好地结合在一起:
- 语义搜索:直接查询非结构化数据,通常使用嵌入或关键词相似性。
- 元数据搜索:对元数据应用结构化查询,过滤特定文档。
向量存储对元数据过滤的支持通常取决于底层向量存储的实现。
以下是使用 Pinecone 的示例,展示了我们过滤所有元数据键 source 值为 tweet 的文档。
await vectorstore.similaritySearch(
"LangChain 提供了抽象,使使用 LLM 变得简单",
2,
{
// 此字段的参数取决于提供者。
filter: { source: "tweet" },
}
);
- 请参阅 Pinecone 关于使用元数据进行过滤的文档。
- 请参阅支持元数据过滤的 LangChain 向量存储集成列表。
高级搜索和检索技术
尽管像 HNSW 这样的算法在许多情况下为高效的相似性搜索提供了基础,但还可以采用其他技术来提高搜索质量和多样性。 例如,最大边界相关性(MMR)是一种重新排序算法,用于多样化搜索结果,它在初始相似性搜索之后应用,以确保结果集更加多样化。
| 名称 | 使用时机 | 描述 |
|---|---|---|
| 最大边界相关性(MMR) | 需要多样化搜索结果时。 | MMR 试图多样化搜索结果,以避免返回相似且冗余的文档。 |