构建一个检索增强生成(RAG)应用:第2部分
在许多问答应用中,我们希望允许用户进行来回对话,这意味着应用程序需要对过去的问题和答案有一定的“记忆”,并需要一些逻辑来将这些信息纳入当前的思考中。
这是一个多部分教程的第二部分:
在这里,我们重点介绍添加用于整合历史消息的逻辑。这涉及聊天历史的管理。
我们将介绍两种方法:
- 链(Chains),其中我们最多执行一个检索步骤;
- 代理(Agents),其中我们赋予 LLM 自主决定执行多个检索步骤的权限。
对于外部知识源,我们将使用 Lilian Weng 撰写的同一篇博客文章LLM 驱动的自主代理,该文章在 RAG 教程的第 1 部分中已使用过。
环境配置
组件
我们需要从 LangChain 的集成套件中选择三个组件。
一个 聊天模型:
Pick your chat model:
- Groq
- OpenAI
- Anthropic
- Google Gemini
- FireworksAI
- MistralAI
- VertexAI
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/groq
yarn add @langchain/groq
pnpm add @langchain/groq
Add environment variables
GROQ_API_KEY=your-api-key
Instantiate the model
import { ChatGroq } from "@langchain/groq";
const llm = new ChatGroq({
model: "llama-3.3-70b-versatile",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/openai
yarn add @langchain/openai
pnpm add @langchain/openai
Add environment variables
OPENAI_API_KEY=your-api-key
Instantiate the model
import { ChatOpenAI } from "@langchain/openai";
const llm = new ChatOpenAI({
model: "gpt-4o-mini",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/anthropic
yarn add @langchain/anthropic
pnpm add @langchain/anthropic
Add environment variables
ANTHROPIC_API_KEY=your-api-key
Instantiate the model
import { ChatAnthropic } from "@langchain/anthropic";
const llm = new ChatAnthropic({
model: "claude-3-5-sonnet-20240620",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-genai
yarn add @langchain/google-genai
pnpm add @langchain/google-genai
Add environment variables
GOOGLE_API_KEY=your-api-key
Instantiate the model
import { ChatGoogleGenerativeAI } from "@langchain/google-genai";
const llm = new ChatGoogleGenerativeAI({
model: "gemini-2.0-flash",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
Add environment variables
FIREWORKS_API_KEY=your-api-key
Instantiate the model
import { ChatFireworks } from "@langchain/community/chat_models/fireworks";
const llm = new ChatFireworks({
model: "accounts/fireworks/models/llama-v3p1-70b-instruct",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/mistralai
yarn add @langchain/mistralai
pnpm add @langchain/mistralai
Add environment variables
MISTRAL_API_KEY=your-api-key
Instantiate the model
import { ChatMistralAI } from "@langchain/mistralai";
const llm = new ChatMistralAI({
model: "mistral-large-latest",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-vertexai
yarn add @langchain/google-vertexai
pnpm add @langchain/google-vertexai
Add environment variables
GOOGLE_APPLICATION_CREDENTIALS=credentials.json
Instantiate the model
import { ChatVertexAI } from "@langchain/google-vertexai";
const llm = new ChatVertexAI({
model: "gemini-1.5-flash",
temperature: 0
});
一个嵌入模型:
Pick your embedding model:
- OpenAI
- Azure
- AWS
- VertexAI
- MistralAI
- Cohere
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/openai
yarn add @langchain/openai
pnpm add @langchain/openai
OPENAI_API_KEY=your-api-key
import { OpenAIEmbeddings } from "@langchain/openai";
const embeddings = new OpenAIEmbeddings({
model: "text-embedding-3-large"
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/openai
yarn add @langchain/openai
pnpm add @langchain/openai
AZURE_OPENAI_API_INSTANCE_NAME=<YOUR_INSTANCE_NAME>
AZURE_OPENAI_API_KEY=<YOUR_KEY>
AZURE_OPENAI_API_VERSION="2024-02-01"
import { AzureOpenAIEmbeddings } from "@langchain/openai";
const embeddings = new AzureOpenAIEmbeddings({
azureOpenAIApiEmbeddingsDeploymentName: "text-embedding-ada-002"
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/aws
yarn add @langchain/aws
pnpm add @langchain/aws
BEDROCK_AWS_REGION=your-region
import { BedrockEmbeddings } from "@langchain/aws";
const embeddings = new BedrockEmbeddings({
model: "amazon.titan-embed-text-v1"
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-vertexai
yarn add @langchain/google-vertexai
pnpm add @langchain/google-vertexai
GOOGLE_APPLICATION_CREDENTIALS=credentials.json
import { VertexAIEmbeddings } from "@langchain/google-vertexai";
const embeddings = new VertexAIEmbeddings({
model: "text-embedding-004"
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/mistralai
yarn add @langchain/mistralai
pnpm add @langchain/mistralai
MISTRAL_API_KEY=your-api-key
import { MistralAIEmbeddings } from "@langchain/mistralai";
const embeddings = new MistralAIEmbeddings({
model: "mistral-embed"
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/cohere
yarn add @langchain/cohere
pnpm add @langchain/cohere
COHERE_API_KEY=your-api-key
import { CohereEmbeddings } from "@langchain/cohere";
const embeddings = new CohereEmbeddings({
model: "embed-english-v3.0"
});
以及一个向量存储:
Pick your vector store:
- Memory
- Chroma
- FAISS
- MongoDB
- PGVector
- Pinecone
- Qdrant
Install dependencies
- npm
- yarn
- pnpm
npm i langchain
yarn add langchain
pnpm add langchain
import { MemoryVectorStore } from "langchain/vectorstores/memory";
const vectorStore = new MemoryVectorStore(embeddings);
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
import { Chroma } from "@langchain/community/vectorstores/chroma";
const vectorStore = new Chroma(embeddings, {
collectionName: "a-test-collection",
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
import { FaissStore } from "@langchain/community/vectorstores/faiss";
const vectorStore = new FaissStore(embeddings, {});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/mongodb
yarn add @langchain/mongodb
pnpm add @langchain/mongodb
import { MongoDBAtlasVectorSearch } from "@langchain/mongodb"
import { MongoClient } from "mongodb";
const client = new MongoClient(process.env.MONGODB_ATLAS_URI || "");
const collection = client
.db(process.env.MONGODB_ATLAS_DB_NAME)
.collection(process.env.MONGODB_ATLAS_COLLECTION_NAME);
const vectorStore = new MongoDBAtlasVectorSearch(embeddings, {
collection: collection,
indexName: "vector_index",
textKey: "text",
embeddingKey: "embedding",
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
import { PGVectorStore } from "@langchain/community/vectorstores/pgvector";
const vectorStore = await PGVectorStore.initialize(embeddings, {})
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/pinecone
yarn add @langchain/pinecone
pnpm add @langchain/pinecone
import { PineconeStore } from "@langchain/pinecone";
import { Pinecone as PineconeClient } from "@pinecone-database/pinecone";
const pinecone = new PineconeClient();
const vectorStore = new PineconeStore(embeddings, {
pineconeIndex,
maxConcurrency: 5,
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/qdrant
yarn add @langchain/qdrant
pnpm add @langchain/qdrant
import { QdrantVectorStore } from "@langchain/qdrant";
const vectorStore = await QdrantVectorStore.fromExistingCollection(embeddings, {
url: process.env.QDRANT_URL,
collectionName: "langchainjs-testing",
});
依赖项
此外,我们将使用以下包:
- npm
- yarn
- pnpm
npm i langchain @langchain/community @langchain/langgraph cheerio
yarn add langchain @langchain/community @langchain/langgraph cheerio
pnpm add langchain @langchain/community @langchain/langgraph cheerio
LangSmith
使用 LangChain 构建的许多应用程序将包含多个步骤,并多次调用 LLM。随着这些应用程序变得越来越复杂,能够检查链或代理内部确切发生的情况变得至关重要。要做到这一点,最好的方法是使用LangSmith。
请注意,LangSmith 并非必需,但它非常有用。如果您确实想使用 LangSmith,在上方链接注册后,请确保设置您的环境变量以开始记录追踪信息:
export LANGSMITH_TRACING=true
export LANGSMITH_API_KEY=您的密钥
# 如果您不在无服务器环境中,可减少追踪延迟
# export LANGCHAIN_CALLBACKS_BACKGROUND=true
链(Chains)
让我们首先回顾一下在第 1 部分中构建的向量存储,它索引了 Lilian Weng 撰写的一篇关于由 LLM 驱动的自主代理的博客文章。
import "cheerio";
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio";
// Load and chunk contents of the blog
const pTagSelector = "p";
const cheerioLoader = new CheerioWebBaseLoader(
"https://lilianweng.github.io/posts/2023-06-23-agent/",
{
selector: pTagSelector,
}
);
const docs = await cheerioLoader.load();
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const allSplits = await splitter.splitDocuments(docs);
// Index chunks
await vectorStore.addDocuments(allSplits);
在 RAG 教程的第一部分中,我们将用户输入、检索到的上下文和生成的答案表示为状态中的独立键。对话体验可以使用消息序列自然地表示。除了用户和助手发送的消息之外,检索到的文档和其他中间结果也可以通过工具消息被纳入消息序列中。这促使我们使用一个消息序列来表示 RAG 应用的状态。具体来说,我们将拥有
- 将用户输入表示为
HumanMessage; - 将向量存储查询表示为包含工具调用的
AIMessage; - 将检索到的文档表示为
ToolMessage; - 将最终回答表示为
AIMessage。
这种状态模型非常灵活,LangGraph 为此提供了一个内置版本,以方便使用:
import { MessagesAnnotation, StateGraph } from "@langchain/langgraph";
const graph = new StateGraph(MessagesAnnotation);
利用工具调用与检索步骤进行交互还有另一个好处,即检索的查询是由我们的模型生成的。这在对话场景中尤其重要,因为用户的查询可能需要根据聊天历史记录进行上下文化处理。例如,请考虑以下对话:
人类:“任务分解是什么?”
AI:“任务分解是指将复杂任务分解为更小、更简单的步骤,以使其对于代理或模型来说更易于处理。”
人类:“通常有哪些方法?”
在这种情况下,模型可以生成诸如"任务分解的常用方法"之类的查询。工具调用可以很好地实现这一点。就像在 RAG 教程的查询分析部分一样,这允许模型将用户查询重写为更有效的搜索查询。它还支持无需检索步骤的直接响应(例如,对用户的通用问候做出回应)。
让我们将检索步骤变成一个工具:
import { z } from "zod";
import { tool } from "@langchain/core/tools";
const retrieveSchema = z.object({ query: z.string() });
const retrieve = tool(
async ({ query }) => {
const retrievedDocs = await vectorStore.similaritySearch(query, 2);
const serialized = retrievedDocs
.map(
(doc) => `Source: ${doc.metadata.source}\nContent: ${doc.pageContent}`
)
.join("\n");
return [serialized, retrievedDocs];
},
{
name: "retrieve",
description: "Retrieve information related to a query.",
schema: retrieveSchema,
responseFormat: "content_and_artifact",
}
);
有关创建工具的详细信息,请参阅本指南。
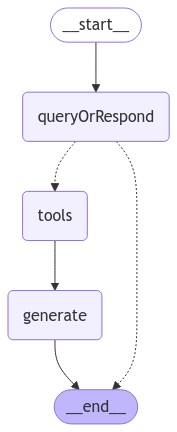
我们的图将包含三个节点:
- 一个处理用户输入的节点,该节点会生成检索器的查询或直接作出响应;
- 一个检索器工具节点,用于执行检索步骤;
- 一个使用检索到的上下文生成最终响应的节点。
我们将在下方构建这些节点。请注意,我们使用了另一个预构建的 LangGraph
组件
ToolNode,它可以执行工具,并将结果作为
ToolMessage 添加到状态中。
import {
AIMessage,
HumanMessage,
SystemMessage,
ToolMessage,
} from "@langchain/core/messages";
import { MessagesAnnotation } from "@langchain/langgraph";
import { ToolNode } from "@langchain/langgraph/prebuilt";
// Step 1: Generate an AIMessage that may include a tool-call to be sent.
async function queryOrRespond(state: typeof MessagesAnnotation.State) {
const llmWithTools = llm.bindTools([retrieve]);
const response = await llmWithTools.invoke(state.messages);
// MessagesState appends messages to state instead of overwriting
return { messages: [response] };
}
// Step 2: Execute the retrieval.
const tools = new ToolNode([retrieve]);
// Step 3: Generate a response using the retrieved content.
async function generate(state: typeof MessagesAnnotation.State) {
// Get generated ToolMessages
let recentToolMessages = [];
for (let i = state["messages"].length - 1; i >= 0; i--) {
let message = state["messages"][i];
if (message instanceof ToolMessage) {
recentToolMessages.push(message);
} else {
break;
}
}
let toolMessages = recentToolMessages.reverse();
// Format into prompt
const docsContent = toolMessages.map((doc) => doc.content).join("\n");
const systemMessageContent =
"You are an assistant for question-answering tasks. " +
"Use the following pieces of retrieved context to answer " +
"the question. If you don't know the answer, say that you " +
"don't know. Use three sentences maximum and keep the " +
"answer concise." +
"\n\n" +
`${docsContent}`;
const conversationMessages = state.messages.filter(
(message) =>
message instanceof HumanMessage ||
message instanceof SystemMessage ||
(message instanceof AIMessage && message.tool_calls.length == 0)
);
const prompt = [
new SystemMessage(systemMessageContent),
...conversationMessages,
];
// Run
const response = await llm.invoke(prompt);
return { messages: [response] };
}
最后,我们将应用程序编译成一个单独的 graph
对象。在这种情况下,我们只是将各个步骤按顺序连接起来。我们还允许第一个
query_or_respond
步骤在未生成工具调用时直接响应用户,从而实现‘短路’功能。这使得我们的应用程序能够支持对话式体验——例如,回应那些可能不需要检索步骤的通用问候语
import { StateGraph } from "@langchain/langgraph";
import { toolsCondition } from "@langchain/langgraph/prebuilt";
const graphBuilder = new StateGraph(MessagesAnnotation)
.addNode("queryOrRespond", queryOrRespond)
.addNode("tools", tools)
.addNode("generate", generate)
.addEdge("__start__", "queryOrRespond")
.addConditionalEdges("queryOrRespond", toolsCondition, {
__end__: "__end__",
tools: "tools",
})
.addEdge("tools", "generate")
.addEdge("generate", "__end__");
const graph = graphBuilder.compile();
// 注意:tslab 只能在 Jupyter Notebook 内部工作。请勿担心自己运行此代码!
import * as tslab from "tslab";
const image = await graph.getGraph().drawMermaidPng();
const arrayBuffer = await image.arrayBuffer();
await tslab.display.png(new Uint8Array(arrayBuffer));
让我们测试我们的应用程序。
点击展开 `prettyPrint` 代码。
import { BaseMessage, isAIMessage } from "@langchain/core/messages";
const prettyPrint = (message: BaseMessage) => {
let txt = `[${message._getType()}]: ${message.content}`;
if ((isAIMessage(message) && message.tool_calls?.length) || 0 > 0) {
const tool_calls = (message as AIMessage)?.tool_calls
?.map((tc) => `- ${tc.name}(${JSON.stringify(tc.args)})`)
.join("\n");
txt += ` \nTools: \n${tool_calls}`;
}
console.log(txt);
};
请注意,它会适当地响应不需要额外检索步骤的消息:
let inputs1 = { messages: [{ role: "user", content: "Hello" }] };
for await (const step of await graph.stream(inputs1, {
streamMode: "values",
})) {
const lastMessage = step.messages[step.messages.length - 1];
prettyPrint(lastMessage);
console.log("-----\n");
}
[human]: Hello
-----
[ai]: Hello! How can I assist you today?
-----
在执行搜索时,我们可以流式传输各个步骤以观察查询生成、检索和答案生成过程:
let inputs2 = {
messages: [{ role: "user", content: "What is Task Decomposition?" }],
};
for await (const step of await graph.stream(inputs2, {
streamMode: "values",
})) {
const lastMessage = step.messages[step.messages.length - 1];
prettyPrint(lastMessage);
console.log("-----\n");
}
[human]: What is Task Decomposition?
-----
[ai]:
Tools:
- retrieve({"query":"Task Decomposition"})
-----
[tool]: Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.Another quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain
Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: System message:Think step by step and reason yourself to the right decisions to make sure we get it right.
You will first lay out the names of the core classes, functions, methods that will be necessary, as well as a quick comment on their purpose.Then you will output the content of each file including ALL code.
Each file must strictly follow a markdown code block format, where the following tokens must be replaced such that
FILENAME is the lowercase file name including the file extension,
LANG is the markup code block language for the code’s language, and CODE is the code:FILENAMEYou will start with the “entrypoint” file, then go to the ones that are imported by that file, and so on.
Please note that the code should be fully functional. No placeholders.Follow a language and framework appropriate best practice file naming convention.
Make sure that files contain all imports, types etc. Make sure that code in different files are compatible with each other.
-----
[ai]: Task decomposition is the process of breaking down a complex task into smaller, more manageable steps or subgoals. This can be achieved through various methods, such as using prompts for large language models (LLMs), task-specific instructions, or human inputs. It helps in simplifying the problem-solving process and enhances understanding of the task at hand.
-----
点击此处查看 LangSmith 的追踪信息。
对话历史的状态管理
本教程的这一部分之前使用了 RunnableWithMessageHistory 抽象。您可以在 v0.2 文档 中访问该版本的文档。
从 LangChain 的 v0.3 版本开始,我们建议 LangChain 用户使用 LangGraph 持久化 来在新的 LangChain 应用中集成 memory 功能。
如果您的代码已经依赖 RunnableWithMessageHistory 或 BaseChatMessageHistory,则无需进行任何更改。我们近期不计划弃用此功能,因为它适用于简单的聊天应用,并且任何使用 RunnableWithMessageHistory 的代码将继续按预期运行。
请参阅 如何迁移到 LangGraph Memory 了解详细信息。
在生产环境中,问答应用通常会将聊天历史持久化到数据库中,并能够适当地读取和更新它。
LangGraph 实现了一个内置的 持久化层,使其非常适合支持多轮对话的聊天应用。
为了管理多个对话轮次和线程,我们要做的所有事情就是在编译应用时指定一个 checkpointer。由于我们图中的节点正在向状态追加消息,因此我们可以在多次调用之间保持一致的聊天历史。
LangGraph 提供了一个简单的内存 checkpointer,我们在下面使用它。请参见其 文档 获取更多详细信息,包括如何使用不同的持久化后端(例如 SQLite 或 Postgres)。
如需详细了解如何管理消息历史,请前往 如何添加消息历史(memory) 指南。
import { MemorySaver } from "@langchain/langgraph";
const checkpointer = new MemorySaver();
const graphWithMemory = graphBuilder.compile({ checkpointer });
// Specify an ID for the thread
const threadConfig = {
configurable: { thread_id: "abc123" },
streamMode: "values" as const,
};
我们现在可以像之前一样调用:
let inputs3 = {
messages: [{ role: "user", content: "What is Task Decomposition?" }],
};
for await (const step of await graphWithMemory.stream(inputs3, threadConfig)) {
const lastMessage = step.messages[step.messages.length - 1];
prettyPrint(lastMessage);
console.log("-----\n");
}
[human]: What is Task Decomposition?
-----
[ai]:
Tools:
- retrieve({"query":"Task Decomposition"})
-----
[tool]: Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.Another quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain
Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: System message:Think step by step and reason yourself to the right decisions to make sure we get it right.
You will first lay out the names of the core classes, functions, methods that will be necessary, as well as a quick comment on their purpose.Then you will output the content of each file including ALL code.
Each file must strictly follow a markdown code block format, where the following tokens must be replaced such that
FILENAME is the lowercase file name including the file extension,
LANG is the markup code block language for the code’s language, and CODE is the code:FILENAMEYou will start with the “entrypoint” file, then go to the ones that are imported by that file, and so on.
Please note that the code should be fully functional. No placeholders.Follow a language and framework appropriate best practice file naming convention.
Make sure that files contain all imports, types etc. Make sure that code in different files are compatible with each other.
-----
[ai]: Task decomposition is the process of breaking down a complex task into smaller, more manageable steps or subgoals. This can be achieved through various methods, such as using prompts for large language models (LLMs), task-specific instructions, or human inputs. It helps in simplifying the problem-solving process and enhances understanding of the task at hand.
-----
let inputs4 = {
messages: [
{ role: "user", content: "Can you look up some common ways of doing it?" },
],
};
for await (const step of await graphWithMemory.stream(inputs4, threadConfig)) {
const lastMessage = step.messages[step.messages.length - 1];
prettyPrint(lastMessage);
console.log("-----\n");
}
[human]: Can you look up some common ways of doing it?
-----
[ai]:
Tools:
- retrieve({"query":"common methods of task decomposition"})
-----
[tool]: Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.Another quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain
Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: be provided by other developers (as in Plugins) or self-defined (as in function calls).HuggingGPT (Shen et al. 2023) is a framework to use ChatGPT as the task planner to select models available in HuggingFace platform according to the model descriptions and summarize the response based on the execution results.The system comprises of 4 stages:(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.Instruction:(2) Model selection: LLM distributes the tasks to expert models, where the request is framed as a multiple-choice question. LLM is presented with a list of models to choose from. Due to the limited context length, task type based filtration is needed.Instruction:(3) Task execution: Expert models execute on the specific tasks and log results.Instruction:(4) Response generation:
-----
[ai]: Common ways of task decomposition include using large language models (LLMs) with simple prompts like "Steps for XYZ" or "What are the subgoals for achieving XYZ?", employing task-specific instructions (e.g., "Write a story outline"), and incorporating human inputs. Additionally, methods like the Tree of Thoughts approach explore multiple reasoning possibilities at each step, creating a structured tree of thoughts. These techniques facilitate breaking down tasks into manageable components for better execution.
-----
请注意,模型在第二个问题中生成的查询包含了对话上下文。
此处的 LangSmith 追踪尤其具有参考价值,因为我们可以清楚地看到在每一步中我们的聊天模型可见的消息内容。
代理
代理 利用 LLM 的推理能力在执行过程中进行决策。使用代理可以将更多检索过程的判断权下放。尽管其行为比上述“链”更难以预测,但它们能够执行多个检索步骤以服务于一个查询,或者对单次搜索进行迭代。
下面我们构建了一个最简化的 RAG 代理。使用 LangGraph 的预构建 ReAct 代理构造器,我们可以在一行代码中完成此操作。
:::提示
查看LangGraph的 Agentic RAG 教程以了解更多高级用法。
:::
import { createReactAgent } from "@langchain/langgraph/prebuilt";
const agent = createReactAgent({ llm: llm, tools: [retrieve] });
让我们检查一下这个图表:
// 注意:tslab 只能在 Jupyter Notebook 内部运行。请勿担心自行运行此代码!
import * as tslab from "tslab";
const image = await agent.getGraph().drawMermaidPng();
const arrayBuffer = await image.arrayBuffer();
await tslab.display.png(new Uint8Array(arrayBuffer));

与我们之前实现的主要区别在于,这里不是以一个最终生成步骤结束运行,而是将工具调用循环回到原始的 LLM 调用。这样,模型可以使用检索到的上下文来回答问题,或者生成另一个工具调用来获取更多信息。
让我们来测试一下这个方法。我们构建了一个通常需要通过迭代检索步骤来解答的问题:
let inputMessage = `What is the standard method for Task Decomposition?
Once you get the answer, look up common extensions of that method.`;
let inputs5 = { messages: [{ role: "user", content: inputMessage }] };
for await (const step of await agent.stream(inputs5, {
streamMode: "values",
})) {
const lastMessage = step.messages[step.messages.length - 1];
prettyPrint(lastMessage);
console.log("-----\n");
}
[human]: What is the standard method for Task Decomposition?
Once you get the answer, look up common extensions of that method.
-----
[ai]:
Tools:
- retrieve({"query":"standard method for Task Decomposition"})
-----
[tool]: Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.Another quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain
Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: System message:Think step by step and reason yourself to the right decisions to make sure we get it right.
You will first lay out the names of the core classes, functions, methods that will be necessary, as well as a quick comment on their purpose.Then you will output the content of each file including ALL code.
Each file must strictly follow a markdown code block format, where the following tokens must be replaced such that
FILENAME is the lowercase file name including the file extension,
LANG is the markup code block language for the code’s language, and CODE is the code:FILENAMEYou will start with the “entrypoint” file, then go to the ones that are imported by that file, and so on.
Please note that the code should be fully functional. No placeholders.Follow a language and framework appropriate best practice file naming convention.
Make sure that files contain all imports, types etc. Make sure that code in different files are compatible with each other.
-----
[ai]:
Tools:
- retrieve({"query":"common extensions of Task Decomposition method"})
-----
[tool]: Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.Another quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain
Source: https://lilianweng.github.io/posts/2023-06-23-agent/
Content: be provided by other developers (as in Plugins) or self-defined (as in function calls).HuggingGPT (Shen et al. 2023) is a framework to use ChatGPT as the task planner to select models available in HuggingFace platform according to the model descriptions and summarize the response based on the execution results.The system comprises of 4 stages:(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.Instruction:(2) Model selection: LLM distributes the tasks to expert models, where the request is framed as a multiple-choice question. LLM is presented with a list of models to choose from. Due to the limited context length, task type based filtration is needed.Instruction:(3) Task execution: Expert models execute on the specific tasks and log results.Instruction:(4) Response generation:
-----
[ai]: ### Standard Method for Task Decomposition
The standard method for task decomposition involves breaking down hard tasks into smaller, more manageable steps. This can be achieved through various approaches:
1. **Chain of Thought (CoT)**: This method transforms large tasks into multiple manageable tasks, providing insight into the model's reasoning process.
2. **Prompting**: Using simple prompts like "Steps for XYZ" or "What are the subgoals for achieving XYZ?" to guide the decomposition.
3. **Task-Specific Instructions**: Providing specific instructions tailored to the task, such as "Write a story outline" for writing a novel.
4. **Human Inputs**: Involving human input to assist in the decomposition process.
### Common Extensions of Task Decomposition
Several extensions have been developed to enhance the task decomposition process:
1. **Tree of Thoughts (ToT)**: This method extends CoT by exploring multiple reasoning possibilities at each step. It decomposes the problem into multiple thought steps and generates various thoughts per step, creating a tree structure. The search process can utilize either breadth-first search (BFS) or depth-first search (DFS), with each state evaluated by a classifier or through majority voting.
2. **LLM+P**: This approach involves using an external classical planner for long-horizon planning, integrating planning domains to enhance the decomposition process.
3. **HuggingGPT**: This framework utilizes ChatGPT as a task planner to select models from the HuggingFace platform based on model descriptions. It consists of four stages:
- **Task Planning**: Parsing user requests into multiple tasks with attributes like task type, ID, dependencies, and arguments.
- **Model Selection**: Distributing tasks to expert models based on a multiple-choice question format.
- **Task Execution**: Expert models execute specific tasks and log results.
- **Response Generation**: Compiling the results into a coherent response.
These extensions aim to improve the efficiency and effectiveness of task decomposition, making it easier to manage complex tasks.
-----
请注意,该智能体:
- 生成一个查询以搜索任务分解的标准方法;
- 收到答案后,生成第二个查询以搜索其常见扩展;
- 在收到所有必要的上下文后,回答问题。
我们可以在LangSmith 追踪中看到完整的步骤序列,以及延迟和其他元数据。
后续步骤
我们已经介绍了构建基本对话式问答应用程序的步骤:
- 我们使用链(chains)构建了一个可预测的应用程序,每个用户输入最多生成一个查询;
- 我们使用智能体(agents)构建了一个可以在一系列查询上进行迭代的应用程序。
要探索不同类型的检索器和检索策略,请访问如何指南中的检索器部分。
有关 LangChain 对话内存抽象的详细演练,请访问如何添加消息历史记录(内存)指南。