文本摘要
本教程演示了使用内置链和 LangGraph 进行文本摘要。
有关此页面的先前版本,请参见 此处,其中展示了旧版链 RefineDocumentsChain。
假设你有一组文档(PDF、Notion 页面、客户问题等),并且希望对内容进行摘要。
鉴于 LLM 在理解和合成文本方面的优势,它是完成此任务的理想工具。
在 检索增强生成 的上下文中,文本摘要可以帮助提炼大量检索文档中的信息,从而为 LLM 提供上下文。
在本教程中,我们将介绍如何使用 LLM 对多个文档的内容进行摘要。
概念
我们将涵盖的概念包括:
使用 语言模型。
使用 文档加载器,特别是 CheerioWebBaseLoader 来加载 HTML 网页内容。
两种摘要或合并文档的方法。
- 填充(Stuff),即将文档简单地拼接到一个提示中;
- 映射-归约(Map-reduce),适用于较大的文档集合。这种方法将文档分成批次进行摘要,然后对这些摘要进行汇总。
准备工作
Jupyter Notebook
本教程及其他教程可能最方便在 Jupyter Notebook 中运行。在交互式环境中学习指南是更好地理解它们的好方法。请参见 此处 获取安装说明。
安装
要安装 LangChain,请运行:
bash npm2yarn npm i langchain @langchain/core
有关更多细节,请参见我们的 安装指南。
LangSmith
你使用 LangChain 构建的许多应用程序将包含多个步骤,涉及多次调用 LLM。 随着这些应用程序变得越来越复杂,能够检查链或代理内部发生了什么变得至关重要。 实现这一点的最佳方法是使用 LangSmith。
在上面的链接注册后,请确保设置你的环境变量以开始记录跟踪:
export LANGSMITH_TRACING="true"
export LANGSMITH_API_KEY="..."
# 如果你不在无服务器环境中,可以减少跟踪延迟
# export LANGCHAIN_CALLBACKS_BACKGROUND=true
概览
构建摘要器的一个核心问题是,如何将你的文档传递到 LLM 的上下文窗口中。常见的两种方法是:
填充(Stuff):简单地将所有文档“填充”到一个提示中。这是最简单的方法。映射-归约(Map-reduce):在“映射”步骤中单独摘要每个文档,然后将这些摘要“归约”为最终摘要。
请注意,当子文档的理解不依赖于先前上下文时,映射-归约特别有效。例如,当摘要许多较短的文档时。在其他情况下,如摘要一本小说或具有固有序列的文本体,迭代优化 可能更有效。
首先,我们加载文档。我们将使用 WebBaseLoader 来加载一篇博客文章:
import "cheerio";
import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio";
const pTagSelector = "p";
const cheerioLoader = new CheerioWebBaseLoader(
"https://lilianweng.github.io/posts/2023-06-23-agent/",
{
selector: pTagSelector,
}
);
const docs = await cheerioLoader.load();
接下来,我们选择一个 聊天模型:
Pick your chat model:
- Groq
- OpenAI
- Anthropic
- Google Gemini
- FireworksAI
- MistralAI
- VertexAI
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/groq
yarn add @langchain/groq
pnpm add @langchain/groq
Add environment variables
GROQ_API_KEY=your-api-key
Instantiate the model
import { ChatGroq } from "@langchain/groq";
const llm = new ChatGroq({
model: "llama-3.3-70b-versatile",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/openai
yarn add @langchain/openai
pnpm add @langchain/openai
Add environment variables
OPENAI_API_KEY=your-api-key
Instantiate the model
import { ChatOpenAI } from "@langchain/openai";
const llm = new ChatOpenAI({
model: "gpt-4o-mini",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/anthropic
yarn add @langchain/anthropic
pnpm add @langchain/anthropic
Add environment variables
ANTHROPIC_API_KEY=your-api-key
Instantiate the model
import { ChatAnthropic } from "@langchain/anthropic";
const llm = new ChatAnthropic({
model: "claude-3-5-sonnet-20240620",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-genai
yarn add @langchain/google-genai
pnpm add @langchain/google-genai
Add environment variables
GOOGLE_API_KEY=your-api-key
Instantiate the model
import { ChatGoogleGenerativeAI } from "@langchain/google-genai";
const llm = new ChatGoogleGenerativeAI({
model: "gemini-2.0-flash",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
Add environment variables
FIREWORKS_API_KEY=your-api-key
Instantiate the model
import { ChatFireworks } from "@langchain/community/chat_models/fireworks";
const llm = new ChatFireworks({
model: "accounts/fireworks/models/llama-v3p1-70b-instruct",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/mistralai
yarn add @langchain/mistralai
pnpm add @langchain/mistralai
Add environment variables
MISTRAL_API_KEY=your-api-key
Instantiate the model
import { ChatMistralAI } from "@langchain/mistralai";
const llm = new ChatMistralAI({
model: "mistral-large-latest",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-vertexai
yarn add @langchain/google-vertexai
pnpm add @langchain/google-vertexai
Add environment variables
GOOGLE_APPLICATION_CREDENTIALS=credentials.json
Instantiate the model
import { ChatVertexAI } from "@langchain/google-vertexai";
const llm = new ChatVertexAI({
model: "gemini-1.5-flash",
temperature: 0
});
填充:在单个 LLM 调用中摘要
我们可以使用 createStuffDocumentsChain,尤其是在使用较大的上下文窗口模型时,例如:
- 128k token 的 OpenAI
gpt-4o - 200k token 的 Anthropic
claude-3-5-sonnet-20240620
该链将接收一个文档列表,将它们全部插入到一个提示中,并将该提示传递给 LLM:
import { createStuffDocumentsChain } from "langchain/chains/combine_documents";
import { StringOutputParser } from "@langchain/core/output_parsers";
import { PromptTemplate } from "@langchain/core/prompts";
// 定义提示
const prompt = PromptTemplate.fromTemplate(
"总结这些检索到的文档中的主要主题:{context}"
);
// 实例化
const chain = await createStuffDocumentsChain({
llm: llm,
outputParser: new StringOutputParser(),
prompt,
});
// 调用
const result = await chain.invoke({ context: docs });
console.log(result);
检索到的文档讨论了由大型语言模型 (LLM) 驱动的自主代理的发展和能力。以下是主要主题:
1. **LLM 作为核心控制器**:LLM 被定位为自主代理系统中的核心智能,能够执行超出简单文本生成的复杂任务。它们可以被框架化为通用问题解决者,各种实现如 AutoGPT、GPT-Engineer 和 BabyAGI 展示了其概念验证。
2. **任务分解与规划**:有效的任务管理对于 LLM 至关重要。强调了分解复杂任务的技巧,如思维链 (CoT) 和思维树 (ToT)。CoT 鼓励逐步推理,而 ToT 探索多种推理路径,增强了代理的问题解决能力。
3. **外部工具的集成**:外部工具的使用显著增强了 LLM 的能力。MRKL 和 Toolformer 等框架允许 LLM 与各种 API 和工具交互,提高其在特定任务中的性能。这种模块化方法使 LLM 能够将查询路由到专门模块,结合神经和符号推理。
4. **自我反思与学习**:自我反思机制对于代理从过去的行为中学习并随时间改进至关重要。ReAct 和 Reflexion 等方法将推理与行动结合,使代理能够评估其表现,并根据反馈调整策略。
5. **记忆与上下文管理**:文档讨论了不同类型的记忆(感官记忆、短期记忆、长期记忆)及其与 LLM 的相关性。强调了 LLM 上下文长度有限的挑战,因为它限制了有效保留和利用历史信息的能力。建议使用外部记忆存储和向量数据库等技术来缓解这些限制。
6. **挑战与限制**:识别出若干挑战,包括自然语言接口的可靠性、长期规划的困难以及稳健任务分解的需求。文档指出,LLM 可能会在意外错误和格式问题上遇到困难,这会妨碍其在实际应用中的表现。
7. **新兴应用**:探讨了 LLM 驱动代理的潜在应用,包括科学发现、自主设计和交互式模拟(例如生成代理模仿人类行为)。这些应用展示了 LLM 在各种领域中的多功能性和创新潜力。
总体而言,文档全面概述了当前 LLM 驱动的自主代理,强调了其能力、方法以及在实际实现中面临的挑战。
流式传输
请注意,我们还可以逐字逐句地流式传输结果:
const stream = await chain.stream({ context: docs });
for await (const token of stream) {
process.stdout.write(token + "|");
}
|检索到的文档讨论了由大型语言模型 (LLM) 驱动的自主代理的发展和能力。以下是主要主题:
|1|.| **|LLM 作为核心控制器**|:LLM 被定位为自主代理系统中的核心智能,能够执行超出简单文本生成的复杂任务。它们可以被框架化为通用问题解决者,各种实现如 AutoGPT、GPT-Engineer 和 BabyAGI 展示了其概念验证。|.
|2|.| **|任务分解与规划**|:有效的任务管理对于 LLM 至关重要。强调了分解复杂任务的技巧,如思维链 (CoT) 和思维树 (ToT)。CoT 鼓励逐步推理,而 ToT 探索多种推理路径,增强了代理的问题解决能力。|.
|3|.| **|自我反思与学习**|:自我反思机制对于代理从过去的行为中学习并随时间改进至关重要。ReAct 和 Reflexion 等方法将推理与行动结合,使代理能够评估其表现,并根据反馈调整策略。|.
|4|.| **|工具利用**|:外部工具的使用显著增强了 LLM 的能力。MRKL 和 Toolformer 等框架允许 LLM 与各种 API 和工具交互,提高其在特定任务中的性能。这种模块化方法使 LLM 能够将查询路由到专门模块,结合神经和符号推理。|.
|5|.| **|记忆与上下文管理**|:文档讨论了不同类型的记忆(感官记忆、短期记忆、长期记忆)及其与 LLM 的相关性。强调了 LLM 上下文长度有限的挑战,因为它限制了有效保留和利用历史信息的能力。建议使用向量存储和近似最近邻 (ANN) 等技术来提高检索速度和记忆管理。|.
|6|.| **|挑战与限制**|:识别出若干挑战,包括自然语言接口的可靠性、长期规划的困难以及稳健任务分解的需求。文档指出,LLM 可能会在意外错误和格式问题上遇到困难,这会妨碍其在实际应用中的表现。|.
|7|.| **|新兴应用**|:探讨了 LLM 驱动代理的潜在应用,包括科学发现、自主设计和交互式模拟(例如生成代理)。这些应用展示了 LLM 在各种领域中的多功能性,从药物发现到社会行为模拟。|.
|总体而言,文档全面概述了当前 LLM 驱动的自主代理,其能力、改进的方法以及在实际应用中面临的挑战。|.
深入探索
- 你可以轻松自定义提示。
- 你可以轻松尝试不同的 LLM(例如,通过
llm参数使用 Claude)。
映射-归约:通过并行化摘要长文本
让我们来解析映射-归约方法。为此,我们首先使用 LLM 将每个文档映射为单独的摘要。然后我们将这些摘要归约或合并为一个最终摘要。
请注意,映射步骤通常在输入文档上并行化。
LangGraph 基于 @langchain/core 构建,支持 映射-归约 工作流程,非常适合解决这个问题:
- LangGraph 允许单独步骤(如连续摘要)流式传输,从而更好地控制执行;
- LangGraph 的 检查点 支持错误恢复,扩展了人工参与的工作流程,并更易于将其集成到对话应用程序中;
- LangGraph 的实现易于修改和扩展,我们将在下面看到。
映射
首先,我们定义与映射步骤相关的提示。我们可以使用与上面 填充
方法相同的摘要提示:
import { ChatPromptTemplate } from "@langchain/core/prompts";
const mapPrompt = ChatPromptTemplate.fromMessages([
["user", "Write a concise summary of the following: \n\n{context}"],
]);
我们还可以使用 Prompt Hub 来存储和获取提示。
这将与你的 LangSmith API 密钥 一起工作。
例如,参见此处的映射提示 here。
import { pull } from "langchain/hub";
import { ChatPromptTemplate } from "@langchain/core/prompts";
const mapPrompt = (await pull) < ChatPromptTemplate > "rlm/map-prompt";
归约
我们还定义了一个提示,该提示接收文档映射结果并将其归约为一个输出。
// 还可以通过 hub 在 `rlm/reduce-prompt` 获取
let reduceTemplate = `
以下是一组摘要:
{docs}
将其提炼为一个最终的、整合的摘要
主要主题。
`;
const reducePrompt = ChatPromptTemplate.fromMessages([
["user", reduceTemplate],
]);
通过 LangGraph 协调
下面,我们实现一个简单的应用程序,将摘要步骤映射到文档列表上,然后使用上述提示将其归约。
当文本相对于 LLM 的上下文窗口较长时,映射-归约流程特别有用。对于长文本,我们需要一种机制,确保在归约步骤中要摘要的上下文不超过模型的上下文窗口大小。在这里,我们实现了一种递归的“折叠”摘要:输入根据一个 token 限制进行分区,并对分区生成摘要。重复此步骤,直到摘要的总长度在期望的限制内,从而可以摘要任意长度的文本。
首先,我们将博客文章分成更小的“子文档”以进行映射:
import { TokenTextSplitter } from "@langchain/textsplitters";
const textSplitter = new TokenTextSplitter({
chunkSize: 1000,
chunkOverlap: 0,
});
const splitDocs = await textSplitter.splitDocuments(docs);
console.log(`生成了 ${splitDocs.length} 个文档。`);
生成了 6 个文档。
接下来,我们定义我们的图。请注意,我们定义了一个人为的低最大 token 长度 1000 以演示“折叠”步骤。
import {
collapseDocs,
splitListOfDocs,
} from "langchain/chains/combine_documents/reduce";
import { Document } from "@langchain/core/documents";
import { StateGraph, Annotation, Send } from "@langchain/langgraph";
let tokenMax = 1000;
async function lengthFunction(documents) {
const tokenCounts = await Promise.all(
documents.map(async (doc) => {
return llm.getNumTokens(doc.pageContent);
})
);
return tokenCounts.reduce((sum, count) => sum + count, 0);
}
const OverallState = Annotation.Root({
contents: Annotation<string[]>,
// 注意此处我们传递了一个归约函数。
// 这是因为我们希望将生成的所有摘要
// 从各个节点合并回一个列表。 - 这本质上
// 是“归约”部分
summaries: Annotation<string[]>({
reducer: (state, update) => state.concat(update),
}),
collapsedSummaries: Annotation<Document[]>,
finalSummary: Annotation<string>,
});
// 这将是我们在节点中将“映射”的文档状态
// 以生成摘要
interface SummaryState {
content: string;
}
// 这里我们生成一个摘要,给定一个文档
const generateSummary = async (
state: SummaryState
): Promise<{ summaries: string[] }> => {
const prompt = await mapPrompt.invoke({ context: state.content });
const response = await llm.invoke(prompt);
return { summaries: [String(response.content)] };
};
// 这里我们定义了映射文档的逻辑
// 我们将在图中使用它作为边缘
const mapSummaries = (state: typeof OverallState.State) => {
// 我们将返回一个 `Send` 对象列表
// 每个 `Send` 对象包含图中节点的名称
// 以及发送到该节点的状态
return state.contents.map(
(content) => new Send("generateSummary", { content })
);
};
const collectSummaries = async (state: typeof OverallState.State) => {
return {
collapsedSummaries: state.summaries.map(
(summary) => new Document({ pageContent: summary })
),
};
};
async function _reduce(input) {
const prompt = await reducePrompt.invoke({ docs: input });
const response = await llm.invoke(prompt);
return String(response.content);
}
// 添加节点来折叠摘要
const collapseSummaries = async (state: typeof OverallState.State) => {
const docLists = splitListOfDocs(
state.collapsedSummaries,
lengthFunction,
tokenMax
);
const results = [];
for (const docList of docLists) {
results.push(await collapseDocs(docList, _reduce));
}
return { collapsedSummaries: results };
};
// 这表示图中的一个条件边,它决定了
// 是否应折叠摘要
async function shouldCollapse(state: typeof OverallState.State) {
let numTokens = await lengthFunction(state.collapsedSummaries);
if (numTokens > tokenMax) {
return "collapseSummaries";
} else {
return "generateFinalSummary";
}
}
// 这里我们将生成最终摘要
const generateFinalSummary = async (state: typeof OverallState.State) => {
const response = await _reduce(state.collapsedSummaries);
return { finalSummary: response };
};
// 构建图
const graph = new StateGraph(OverallState)
.addNode("generateSummary", generateSummary)
.addNode("collectSummaries", collectSummaries)
.addNode("collapseSummaries", collapseSummaries)
.addNode("generateFinalSummary", generateFinalSummary)
.addConditionalEdges("__start__", mapSummaries, ["generateSummary"])
.addEdge("generateSummary", "collectSummaries")
.addConditionalEdges("collectSummaries", shouldCollapse, [
"collapseSummaries",
"generateFinalSummary",
])
.addConditionalEdges("collapseSummaries", shouldCollapse, [
"collapseSummaries",
"generateFinalSummary",
])
.addEdge("generateFinalSummary", "__end__");
const app = graph.compile();
LangGraph 允许绘制图结构以帮助可视化其功能:
// 注意:tslab 只能在 jupyter notebook 中运行。不用担心自己运行此代码!
import * as tslab from "tslab";
const image = await app.getGraph().drawMermaidPng();
const arrayBuffer = await image.arrayBuffer();
await tslab.display.png(new Uint8Array(arrayBuffer));
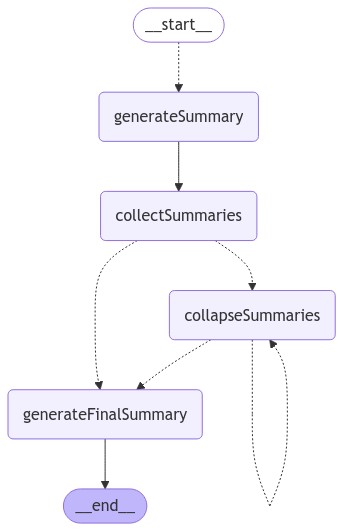
运行应用程序时,我们可以流式传输图以观察其步骤序列。下面,我们只需打印出步骤名称。
请注意,由于图中存在循环,指定 recursion_limit 可能很有帮助。当超过指定限制时,这将引发特定错误。
let finalSummary = null;
for await (const step of await app.stream(
{ contents: splitDocs.map((doc) => doc.pageContent) },
{ recursionLimit: 10 }
)) {
console.log(Object.keys(step));
if (step.hasOwnProperty("generateFinalSummary")) {
finalSummary = step.generateFinalSummary;
}
}
[ 'generateSummary' ]
[ 'generateSummary' ]
[ 'generateSummary' ]
[ 'generateSummary' ]
[ 'generateSummary' ]
[ 'generateSummary' ]
[ 'collectSummaries' ]
[ 'generateFinalSummary' ]
finalSummary;
{
finalSummary: '摘要突出了大型语言模型 (LLM) 及其在自主代理和各种应用中的集成不断发展的前景。关键主题包括:\n' +
'\n' +
'1. **自主代理和 LLM**:像 AutoGPT 和 GPT-Engineer 这样的项目展示了 LLM 在自主系统中作为核心控制器的潜力,使用诸如思维链 (CoT) 和思维树 (ToT) 等技术进行任务管理和推理。这些代理可以通过自我反思机制从过去的行为中学习,从而增强其问题解决能力。\n' +
'\n' +
'2. **监督微调和人类反馈**:强调了人类反馈在微调模型中的重要性,诸如算法蒸馏 (AD) 等方法在提高模型性能的同时防止过拟合方面显示出前景。建议集成各种记忆类型和外部记忆系统以增强认知能力。\n' +
'\n' +
'3. **外部工具的集成**:集成外部工具和 API 显著扩展了 LLM 的能力,特别是在最大内积搜索 (MIPS) 和特定领域应用如 ChemCrow 用于药物发现等专业任务中。MRKL 和 HuggingGPT 等框架展示了 LLM 有效利用这些工具的潜力。\n' +
'\n' +
'4. **评估差异**:LLM 基评估与专家评估之间存在显著差异,表明 LLM 在专业知识方面可能存在问题。这引发了对其在关键应用(如科学发现)中可靠性的担忧。\n' +
'\n' +
'5. **LLM 的局限性**:尽管有进步,LLM 仍面临限制,包括有限的上下文长度、长期规划的挑战以及适应意外错误的困难。这些限制阻碍了其与人类能力相比的稳健性。\n' +
'\n' +
'总体而言,LLM 及其应用的进步揭示了其潜力和局限性,强调了需要持续研究和开发以增强其在各种领域中的有效性。'
}
在对应的 LangSmith 跟踪 中,我们可以看到各个 LLM 调用,按各自的节点分组。
深入探索
自定义
- 如上所示,你可以自定义映射和归约阶段的 LLM 和提示。
现实用例
- 参见 这篇博客文章,分析用户交互(关于 LangChain 文档的问题)的案例研究!
- 该博客文章和相关的 仓库 还介绍了聚类作为一种摘要方法。
- 这为
填充或映射-归约方法之外提供了另一条值得考虑的路径。
下一步
我们鼓励你查看 操作指南 以获取更多详细信息:
以及其他概念。