如何添加聊天历史
本教程之前使用 RunnableWithMessageHistory 构建了一个聊天机器人。你可以在 v0.2 文档 中访问本教程的这个版本。
与 RunnableWithMessageHistory 相比,LangGraph
实现提供了多项优势,包括能够持久化应用程序状态的任意组件(而不仅仅是消息)。
在许多问答应用中,我们希望用户可以进行来回对话,这意味着应用需要对过去的问题和答案具有某种“记忆”,并且需要一些逻辑来将这些信息纳入当前的思考中。
在本指南中,我们重点介绍添加用于整合历史消息的逻辑。
这在很大程度上是 对话式 RAG 教程 的一个精简版本。
我们将介绍两种方法:
- 链(Chains),其中我们始终执行检索步骤;
- 代理(Agents),其中我们赋予 LLM 决定是否以及如何执行检索步骤(或多个步骤)的权限。
对于外部知识源,我们将使用与 RAG 教程 中相同的由 Lilian Weng 撰写的博客文章 LLM Powered Autonomous Agents。
环境配置
依赖项
在本次演示中,我们将使用一个 OpenAI 的聊天模型和嵌入模型,以及一个 Memory 向量存储。但这里展示的内容适用于任何 ChatModel 或 LLM、Embeddings、VectorStore 或 Retriever。
我们将使用以下软件包:
npm install --save langchain @langchain/openai langchain cheerio uuid
我们需要设置环境变量 OPENAI_API_KEY:
export OPENAI_API_KEY=YOUR_KEY
LangSmith
使用 LangChain 构建的许多应用程序将包含多个步骤,并多次调用 LLM。随着这些应用程序变得越来越复杂,能够检查链或代理内部确切发生的情况变得至关重要。最好的方法是使用LangSmith。
请注意,LangSmith 不是必需的,但它非常有帮助。如果您确实想使用 LangSmith,在上面的链接注册后,请确保设置您的环境变量以开始记录跟踪信息:
export LANGSMITH_TRACING=true
export LANGSMITH_API_KEY=您的密钥
# 如果您不在无服务器环境中,请减少跟踪延迟
# export LANGCHAIN_CALLBACKS_BACKGROUND=true
链
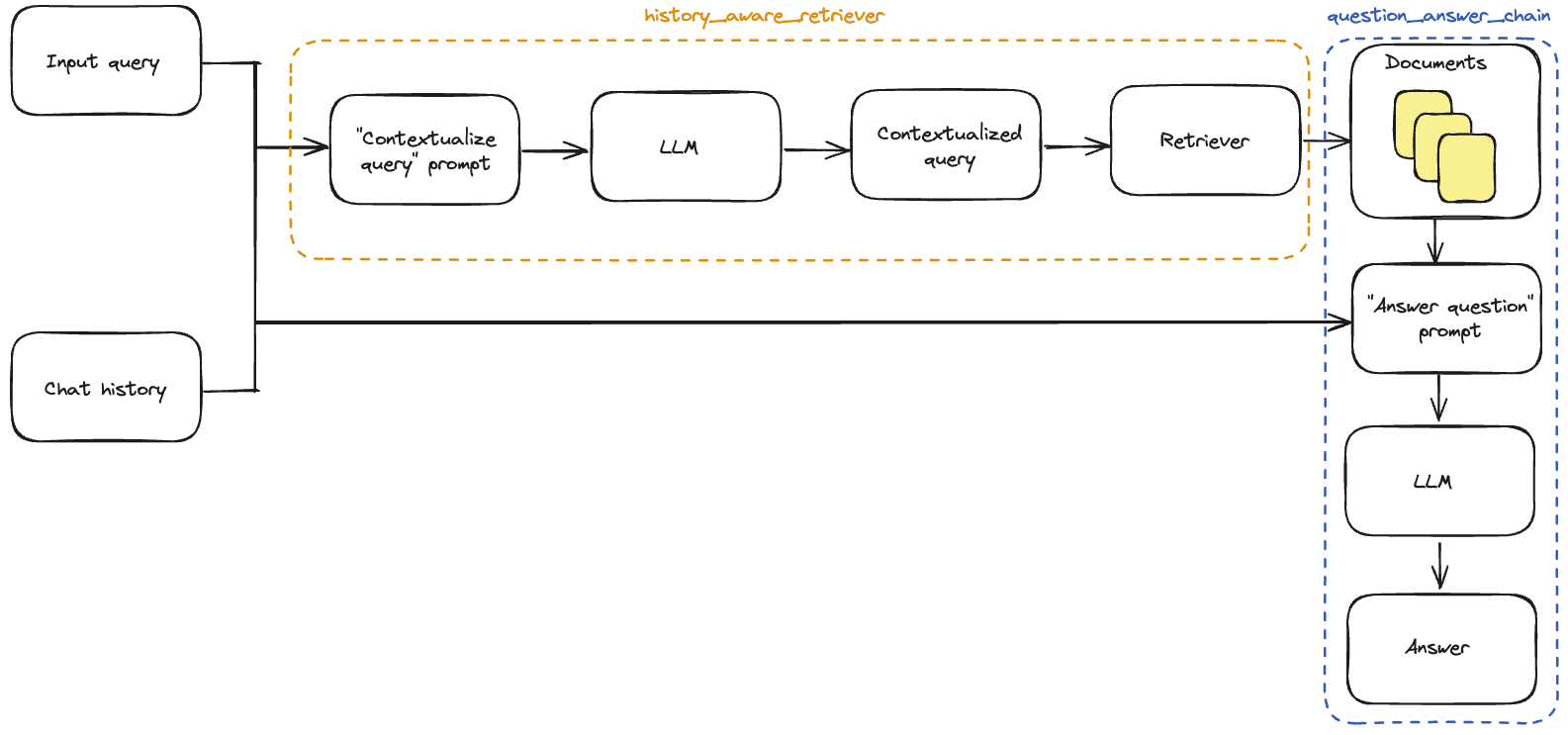
在一个对话式 RAG 应用中,发送给检索器的查询应该基于对话的上下文。LangChain 提供了一个createHistoryAwareRetriever构造函数来简化这一过程。它构建了一个接受键
input 和 chat_history
作为输入的链,并且输出模式与检索器相同。createHistoryAwareRetriever
需要以下输入:
- LLM;
- 检索器;
- 提示词。
首先,我们获取这些对象:
LLM
我们可以使用任何支持的聊天模型:
Pick your chat model:
- Groq
- OpenAI
- Anthropic
- Google Gemini
- FireworksAI
- MistralAI
- VertexAI
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/groq
yarn add @langchain/groq
pnpm add @langchain/groq
Add environment variables
GROQ_API_KEY=your-api-key
Instantiate the model
import { ChatGroq } from "@langchain/groq";
const llm = new ChatGroq({
model: "llama-3.3-70b-versatile",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/openai
yarn add @langchain/openai
pnpm add @langchain/openai
Add environment variables
OPENAI_API_KEY=your-api-key
Instantiate the model
import { ChatOpenAI } from "@langchain/openai";
const llm = new ChatOpenAI({
model: "gpt-4o-mini",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/anthropic
yarn add @langchain/anthropic
pnpm add @langchain/anthropic
Add environment variables
ANTHROPIC_API_KEY=your-api-key
Instantiate the model
import { ChatAnthropic } from "@langchain/anthropic";
const llm = new ChatAnthropic({
model: "claude-3-5-sonnet-20240620",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-genai
yarn add @langchain/google-genai
pnpm add @langchain/google-genai
Add environment variables
GOOGLE_API_KEY=your-api-key
Instantiate the model
import { ChatGoogleGenerativeAI } from "@langchain/google-genai";
const llm = new ChatGoogleGenerativeAI({
model: "gemini-2.0-flash",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
Add environment variables
FIREWORKS_API_KEY=your-api-key
Instantiate the model
import { ChatFireworks } from "@langchain/community/chat_models/fireworks";
const llm = new ChatFireworks({
model: "accounts/fireworks/models/llama-v3p1-70b-instruct",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/mistralai
yarn add @langchain/mistralai
pnpm add @langchain/mistralai
Add environment variables
MISTRAL_API_KEY=your-api-key
Instantiate the model
import { ChatMistralAI } from "@langchain/mistralai";
const llm = new ChatMistralAI({
model: "mistral-large-latest",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-vertexai
yarn add @langchain/google-vertexai
pnpm add @langchain/google-vertexai
Add environment variables
GOOGLE_APPLICATION_CREDENTIALS=credentials.json
Instantiate the model
import { ChatVertexAI } from "@langchain/google-vertexai";
const llm = new ChatVertexAI({
model: "gemini-1.5-flash",
temperature: 0
});
初始设置
import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { OpenAIEmbeddings } from "@langchain/openai";
const loader = new CheerioWebBaseLoader(
"https://lilianweng.github.io/posts/2023-06-23-agent/"
);
const docs = await loader.load();
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const splits = await textSplitter.splitDocuments(docs);
const vectorStore = await MemoryVectorStore.fromDocuments(
splits,
new OpenAIEmbeddings()
);
// Retrieve and generate using the relevant snippets of the blog.
const retriever = vectorStore.asRetriever();
提示词
我们将使用一个提示词,其中包含一个名为 “chat_history” 的
MessagesPlaceholder 变量。这允许我们使用 “chat_history”
输入键向提示词中传入一条消息列表,这些消息将会被插入到系统消息之后,以及包含最新问题的人类消息之前。
import {
ChatPromptTemplate,
MessagesPlaceholder,
} from "@langchain/core/prompts";
const contextualizeQSystemPrompt =
"Given a chat history and the latest user question " +
"which might reference context in the chat history, " +
"formulate a standalone question which can be understood " +
"without the chat history. Do NOT answer the question, " +
"just reformulate it if needed and otherwise return it as is.";
const contextualizeQPrompt = ChatPromptTemplate.fromMessages([
["system", contextualizeQSystemPrompt],
new MessagesPlaceholder("chat_history"),
["human", "{input}"],
]);
组装链
然后我们可以实例化具备历史感知能力的检索器:
import { createHistoryAwareRetriever } from "langchain/chains/history_aware_retriever";
const historyAwareRetriever = await createHistoryAwareRetriever({
llm,
retriever,
rephrasePrompt: contextualizeQPrompt,
});
此链会在检索器前添加对输入查询的改写,以便检索过程能够结合对话的上下文。
现在我们可以构建完整的问答链。
与RAG 教程中一样,我们将使用createStuffDocumentsChain生成一个questionAnswerChain,其输入键为context、chat_history和input——它接受检索到的上下文以及对话历史和查询以生成答案。
我们使用createRetrievalChain构建最终的ragChain。该链依次应用historyAwareRetriever和questionAnswerChain,并保留中间输出(如检索到的上下文)以方便使用。它的输入键为input和chat_history,输出包含input、chat_history、context和answer。
import { createStuffDocumentsChain } from "langchain/chains/combine_documents";
import { createRetrievalChain } from "langchain/chains/retrieval";
const systemPrompt =
"You are an assistant for question-answering tasks. " +
"Use the following pieces of retrieved context to answer " +
"the question. If you don't know the answer, say that you " +
"don't know. Use three sentences maximum and keep the " +
"answer concise." +
"\n\n" +
"{context}";
const qaPrompt = ChatPromptTemplate.fromMessages([
["system", systemPrompt],
new MessagesPlaceholder("chat_history"),
["human", "{input}"],
]);
const questionAnswerChain = await createStuffDocumentsChain({
llm,
prompt: qaPrompt,
});
const ragChain = await createRetrievalChain({
retriever: historyAwareRetriever,
combineDocsChain: questionAnswerChain,
});
聊天历史的有状态管理
我们已经添加了用于整合聊天历史的应用逻辑,但目前仍需手动在整个应用中进行传递。在生产环境中,我们的问答应用通常会将聊天历史持久化到数据库中,并能够适当地读取和更新它。
LangGraph 实现了一个内置的 持久化层,使其非常适合支持多轮对话的聊天应用。
将我们的聊天模型封装在一个最小的 LangGraph 应用中,可以让我们自动持久化消息历史,从而简化多轮对话应用的开发。
LangGraph 配备了一个简单的 内存检查点存储器,我们下面将使用它。有关更多细节(包括如何使用不同的持久化后端,例如 SQLite 或 Postgres),请参阅其文档。
如需详细了解如何管理消息历史,请前往《如何添加消息历史(记忆)》指南。
import { AIMessage, BaseMessage, HumanMessage } from "@langchain/core/messages";
import {
StateGraph,
START,
END,
MemorySaver,
messagesStateReducer,
Annotation,
} from "@langchain/langgraph";
// Define the State interface
const GraphAnnotation = Annotation.Root({
input: Annotation<string>(),
chat_history: Annotation<BaseMessage[]>({
reducer: messagesStateReducer,
default: () => [],
}),
context: Annotation<string>(),
answer: Annotation<string>(),
});
// Define the call_model function
async function callModel(state: typeof GraphAnnotation.State) {
const response = await ragChain.invoke(state);
return {
chat_history: [
new HumanMessage(state.input),
new AIMessage(response.answer),
],
context: response.context,
answer: response.answer,
};
}
// Create the workflow
const workflow = new StateGraph(GraphAnnotation)
.addNode("model", callModel)
.addEdge(START, "model")
.addEdge("model", END);
// Compile the graph with a checkpointer object
const memory = new MemorySaver();
const app = workflow.compile({ checkpointer: memory });
import { v4 as uuidv4 } from "uuid";
const threadId = uuidv4();
const config = { configurable: { thread_id: threadId } };
const result = await app.invoke(
{ input: "What is Task Decomposition?" },
config
);
console.log(result.answer);
Task Decomposition is the process of breaking down a complicated task into smaller, simpler, and more manageable steps. Techniques like Chain of Thought (CoT) and Tree of Thoughts expand on this by enabling agents to think step by step or explore multiple reasoning possibilities at each step. This allows for a more structured and interpretable approach to handling complex tasks.
const result2 = await app.invoke(
{ input: "What is one way of doing it?" },
config
);
console.log(result2.answer);
One way of doing task decomposition is by using an LLM with simple prompting, such as asking "Steps for XYZ.\n1." or "What are the subgoals for achieving XYZ?" This method leverages direct prompts to guide the model in breaking down tasks.
可以通过应用程序的状态检查对话历史记录:
const chatHistory = (await app.getState(config)).values.chat_history;
for (const message of chatHistory) {
console.log(message);
}
HumanMessage {
"content": "What is Task Decomposition?",
"additional_kwargs": {},
"response_metadata": {}
}
AIMessage {
"content": "Task Decomposition is the process of breaking down a complicated task into smaller, simpler, and more manageable steps. Techniques like Chain of Thought (CoT) and Tree of Thoughts expand on this by enabling agents to think step by step or explore multiple reasoning possibilities at each step. This allows for a more structured and interpretable approach to handling complex tasks.",
"additional_kwargs": {},
"response_metadata": {},
"tool_calls": [],
"invalid_tool_calls": []
}
HumanMessage {
"content": "What is one way of doing it?",
"additional_kwargs": {},
"response_metadata": {}
}
AIMessage {
"content": "One way of doing task decomposition is by using an LLM with simple prompting, such as asking \"Steps for XYZ.\\n1.\" or \"What are the subgoals for achieving XYZ?\" This method leverages direct prompts to guide the model in breaking down tasks.",
"additional_kwargs": {},
"response_metadata": {},
"tool_calls": [],
"invalid_tool_calls": []
}
综合运用
为方便起见,我们将所有必要步骤整合到一个代码单元格中:
import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { OpenAIEmbeddings, ChatOpenAI } from "@langchain/openai";
import {
ChatPromptTemplate,
MessagesPlaceholder,
} from "@langchain/core/prompts";
import { createHistoryAwareRetriever } from "langchain/chains/history_aware_retriever";
import { createStuffDocumentsChain } from "langchain/chains/combine_documents";
import { createRetrievalChain } from "langchain/chains/retrieval";
import { AIMessage, BaseMessage, HumanMessage } from "@langchain/core/messages";
import {
StateGraph,
START,
END,
MemorySaver,
messagesStateReducer,
Annotation,
} from "@langchain/langgraph";
import { v4 as uuidv4 } from "uuid";
const llm2 = new ChatOpenAI({ model: "gpt-4o" });
const loader2 = new CheerioWebBaseLoader(
"https://lilianweng.github.io/posts/2023-06-23-agent/"
);
const docs2 = await loader2.load();
const textSplitter2 = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const splits2 = await textSplitter2.splitDocuments(docs2);
const vectorStore2 = await MemoryVectorStore.fromDocuments(
splits2,
new OpenAIEmbeddings()
);
// Retrieve and generate using the relevant snippets of the blog.
const retriever2 = vectorStore2.asRetriever();
const contextualizeQSystemPrompt2 =
"Given a chat history and the latest user question " +
"which might reference context in the chat history, " +
"formulate a standalone question which can be understood " +
"without the chat history. Do NOT answer the question, " +
"just reformulate it if needed and otherwise return it as is.";
const contextualizeQPrompt2 = ChatPromptTemplate.fromMessages([
["system", contextualizeQSystemPrompt2],
new MessagesPlaceholder("chat_history"),
["human", "{input}"],
]);
const historyAwareRetriever2 = await createHistoryAwareRetriever({
llm: llm2,
retriever: retriever2,
rephrasePrompt: contextualizeQPrompt2,
});
const systemPrompt2 =
"You are an assistant for question-answering tasks. " +
"Use the following pieces of retrieved context to answer " +
"the question. If you don't know the answer, say that you " +
"don't know. Use three sentences maximum and keep the " +
"answer concise." +
"\n\n" +
"{context}";
const qaPrompt2 = ChatPromptTemplate.fromMessages([
["system", systemPrompt2],
new MessagesPlaceholder("chat_history"),
["human", "{input}"],
]);
const questionAnswerChain2 = await createStuffDocumentsChain({
llm: llm2,
prompt: qaPrompt2,
});
const ragChain2 = await createRetrievalChain({
retriever: historyAwareRetriever2,
combineDocsChain: questionAnswerChain2,
});
// Define the State interface
const GraphAnnotation2 = Annotation.Root({
input: Annotation<string>(),
chat_history: Annotation<BaseMessage[]>({
reducer: messagesStateReducer,
default: () => [],
}),
context: Annotation<string>(),
answer: Annotation<string>(),
});
// Define the call_model function
async function callModel2(state: typeof GraphAnnotation2.State) {
const response = await ragChain2.invoke(state);
return {
chat_history: [
new HumanMessage(state.input),
new AIMessage(response.answer),
],
context: response.context,
answer: response.answer,
};
}
// Create the workflow
const workflow2 = new StateGraph(GraphAnnotation2)
.addNode("model", callModel2)
.addEdge(START, "model")
.addEdge("model", END);
// Compile the graph with a checkpointer object
const memory2 = new MemorySaver();
const app2 = workflow2.compile({ checkpointer: memory2 });
const threadId2 = uuidv4();
const config2 = { configurable: { thread_id: threadId2 } };
const result3 = await app2.invoke(
{ input: "What is Task Decomposition?" },
config2
);
console.log(result3.answer);
const result4 = await app2.invoke(
{ input: "What is one way of doing it?" },
config2
);
console.log(result4.answer);
Task Decomposition is the process of breaking a complicated task into smaller, simpler steps to enhance model performance on complex tasks. Techniques like Chain of Thought (CoT) and Tree of Thoughts (ToT) are used for this, with CoT focusing on step-by-step thinking and ToT exploring multiple reasoning possibilities at each step. Decomposition can be carried out by the LLM itself, using task-specific instructions, or through human inputs.
One way of doing task decomposition is by prompting the LLM with simple instructions such as "Steps for XYZ.\n1." or "What are the subgoals for achieving XYZ?" This encourages the model to break down the task into smaller, manageable steps on its own.
代理
代理利用 LLM 的推理能力在执行过程中做出决策。使用代理可以让我们将检索过程的部分判断权下放。尽管它们的行为比链(chains)更难预测,但在此背景下它们具有一些优势: - 代理直接生成检索器的输入,而无需我们像上面那样显式地构建上下文化内容; - 代理可以为了满足查询执行多个检索步骤,或者完全不执行任何检索步骤(例如,响应用户的通用问候语)。
检索工具
代理可以访问“工具”并管理其执行。在这种情况下,我们将把检索器转换为 LangChain 工具,供代理使用:
import { createRetrieverTool } from "langchain/tools/retriever";
const tool = createRetrieverTool(retriever, {
name: "blog_post_retriever",
description:
"Searches and returns excerpts from the Autonomous Agents blog post.",
});
const tools = [tool];
代理构造函数
既然我们已经定义了工具和 LLM,现在可以创建代理了。我们将使用LangGraph来构建代理。 目前我们使用的是一个高级接口来构建代理,但 LangGraph 的优点在于,这个高级接口背后有一个低级的、高度可控的 API,以防你想修改代理的逻辑。
import { createReactAgent } from "@langchain/langgraph/prebuilt";
const agentExecutor = createReactAgent({ llm, tools });
我们现在可以尝试一下。请注意,目前它还不是有状态的(我们还需要添加内存支持)
const query = "What is Task Decomposition?";
for await (const s of await agentExecutor.stream({
messages: [{ role: "user", content: query }],
})) {
console.log(s);
console.log("----");
}
{
agent: {
messages: [
AIMessage {
"id": "chatcmpl-AB7xlcJBGSKSp1GvgDY9FP8KvXxwB",
"content": "",
"additional_kwargs": {
"tool_calls": [
{
"id": "call_Ev0nA6nzGwOeMC5upJUUxTuw",
"type": "function",
"function": "[Object]"
}
]
},
"response_metadata": {
"tokenUsage": {
"completionTokens": 19,
"promptTokens": 66,
"totalTokens": 85
},
"finish_reason": "tool_calls",
"system_fingerprint": "fp_52a7f40b0b"
},
"tool_calls": [
{
"name": "blog_post_retriever",
"args": {
"query": "Task Decomposition"
},
"type": "tool_call",
"id": "call_Ev0nA6nzGwOeMC5upJUUxTuw"
}
],
"invalid_tool_calls": [],
"usage_metadata": {
"input_tokens": 66,
"output_tokens": 19,
"total_tokens": 85
}
}
]
}
}
----
{
tools: {
messages: [
ToolMessage {
"content": "Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\nTree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\n\nTask decomposition can be done (1) by LLM with simple prompting like \"Steps for XYZ.\\n1.\", \"What are the subgoals for achieving XYZ?\", (2) by using task-specific instructions; e.g. \"Write a story outline.\" for writing a novel, or (3) with human inputs.\nAnother quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain Definition Language (PDDL) as an intermediate interface to describe the planning problem. In this process, LLM (1) translates the problem into “Problem PDDL”, then (2) requests a classical planner to generate a PDDL plan based on an existing “Domain PDDL”, and finally (3) translates the PDDL plan back into natural language. Essentially, the planning step is outsourced to an external tool, assuming the availability of domain-specific PDDL and a suitable planner which is common in certain robotic setups but not in many other domains.\nSelf-Reflection#\n\nAgent System Overview\n \n Component One: Planning\n \n \n Task Decomposition\n \n Self-Reflection\n \n \n Component Two: Memory\n \n \n Types of Memory\n \n Maximum Inner Product Search (MIPS)\n \n \n Component Three: Tool Use\n \n Case Studies\n \n \n Scientific Discovery Agent\n \n Generative Agents Simulation\n \n Proof-of-Concept Examples\n \n \n Challenges\n \n Citation\n \n References\n\n(3) Task execution: Expert models execute on the specific tasks and log results.\nInstruction:\n\nWith the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path.",
"name": "blog_post_retriever",
"additional_kwargs": {},
"response_metadata": {},
"tool_call_id": "call_Ev0nA6nzGwOeMC5upJUUxTuw"
}
]
}
}
----
{
agent: {
messages: [
AIMessage {
"id": "chatcmpl-AB7xmiPNPbMX2KvZKHM2oPfcoFMnY",
"content": "**Task Decomposition** involves breaking down a complicated or large task into smaller, more manageable subtasks. Here are some insights based on current techniques and research:\n\n1. **Chain of Thought (CoT)**:\n - Introduced by Wei et al. (2022), this technique prompts the model to \"think step by step\".\n - It helps decompose hard tasks into several simpler steps.\n - Enhances the interpretability of the model's thought process.\n\n2. **Tree of Thoughts (ToT)**:\n - An extension of CoT by Yao et al. (2023).\n - Decomposes problems into multiple thought steps and generates several possibilities at each step.\n - Utilizes tree structures through BFS (Breadth-First Search) or DFS (Depth-First Search) with evaluation by a classifier or majority vote.\n\n3. **Methods of Task Decomposition**:\n - **Simple Prompting**: Asking the model directly, e.g., \"Steps for XYZ.\\n1.\" or \"What are the subgoals for achieving XYZ?\".\n - **Task-Specific Instructions**: Tailoring instructions to the task, such as \"Write a story outline\" for writing a novel.\n - **Human Inputs**: Receiving inputs from humans to refine the process.\n\n4. **LLM+P Approach**:\n - Suggested by Liu et al. (2023), combines language models with an external classical planner.\n - Uses Planning Domain Definition Language (PDDL) for long-horizon planning:\n 1. Translates the problem into a PDDL problem.\n 2. Requests an external planner to generate a PDDL plan.\n 3. Translates the PDDL plan back into natural language.\n - This method offloads the planning complexity to a specialized tool, especially relevant for domains utilizing robotic setups.\n\nTask Decomposition is a fundamental component of planning in autonomous agent systems, aiding in the efficient accomplishment of complex tasks by breaking them into smaller, actionable steps.",
"additional_kwargs": {},
"response_metadata": {
"tokenUsage": {
"completionTokens": 411,
"promptTokens": 732,
"totalTokens": 1143
},
"finish_reason": "stop",
"system_fingerprint": "fp_e375328146"
},
"tool_calls": [],
"invalid_tool_calls": [],
"usage_metadata": {
"input_tokens": 732,
"output_tokens": 411,
"total_tokens": 1143
}
}
]
}
}
----
LangGraph 自带内置持久化功能,因此我们无需使用
ChatMessageHistory!相反,我们可以直接向 LangGraph
代理传入一个检查点器。
不同的对话通过在配置对象中为对话线程指定一个键来管理,如下所示。
import { MemorySaver } from "@langchain/langgraph";
const memory3 = new MemorySaver();
const agentExecutor2 = createReactAgent({
llm,
tools,
checkpointSaver: memory3,
});
这就是我们构建一个对话式 RAG 代理所需的所有内容。
让我们观察它的行为。请注意,如果我们输入一个不需要检索步骤的查询,代理将不会执行检索步骤:
const threadId3 = uuidv4();
const config3 = { configurable: { thread_id: threadId3 } };
for await (const s of await agentExecutor2.stream(
{ messages: [{ role: "user", content: "Hi! I'm bob" }] },
config3
)) {
console.log(s);
console.log("----");
}
{
agent: {
messages: [
AIMessage {
"id": "chatcmpl-AB7y8P8AGHkxOwKpwMc3qj6r0skYr",
"content": "Hello, Bob! How can I assist you today?",
"additional_kwargs": {},
"response_metadata": {
"tokenUsage": {
"completionTokens": 12,
"promptTokens": 64,
"totalTokens": 76
},
"finish_reason": "stop",
"system_fingerprint": "fp_e375328146"
},
"tool_calls": [],
"invalid_tool_calls": [],
"usage_metadata": {
"input_tokens": 64,
"output_tokens": 12,
"total_tokens": 76
}
}
]
}
}
----
此外,如果我们输入一个需要检索步骤的查询,代理将生成工具的输入:
const query2 = "What is Task Decomposition?";
for await (const s of await agentExecutor2.stream(
{ messages: [{ role: "user", content: query2 }] },
config3
)) {
console.log(s);
console.log("----");
}
{
agent: {
messages: [
AIMessage {
"id": "chatcmpl-AB7y8Do2IHJ2rnUvvMU3pTggmuZud",
"content": "",
"additional_kwargs": {
"tool_calls": [
{
"id": "call_3tSaOZ3xdKY4miIJdvBMR80V",
"type": "function",
"function": "[Object]"
}
]
},
"response_metadata": {
"tokenUsage": {
"completionTokens": 19,
"promptTokens": 89,
"totalTokens": 108
},
"finish_reason": "tool_calls",
"system_fingerprint": "fp_e375328146"
},
"tool_calls": [
{
"name": "blog_post_retriever",
"args": {
"query": "Task Decomposition"
},
"type": "tool_call",
"id": "call_3tSaOZ3xdKY4miIJdvBMR80V"
}
],
"invalid_tool_calls": [],
"usage_metadata": {
"input_tokens": 89,
"output_tokens": 19,
"total_tokens": 108
}
}
]
}
}
----
{
tools: {
messages: [
ToolMessage {
"content": "Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\nTree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\n\nTask decomposition can be done (1) by LLM with simple prompting like \"Steps for XYZ.\\n1.\", \"What are the subgoals for achieving XYZ?\", (2) by using task-specific instructions; e.g. \"Write a story outline.\" for writing a novel, or (3) with human inputs.\nAnother quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain Definition Language (PDDL) as an intermediate interface to describe the planning problem. In this process, LLM (1) translates the problem into “Problem PDDL”, then (2) requests a classical planner to generate a PDDL plan based on an existing “Domain PDDL”, and finally (3) translates the PDDL plan back into natural language. Essentially, the planning step is outsourced to an external tool, assuming the availability of domain-specific PDDL and a suitable planner which is common in certain robotic setups but not in many other domains.\nSelf-Reflection#\n\nAgent System Overview\n \n Component One: Planning\n \n \n Task Decomposition\n \n Self-Reflection\n \n \n Component Two: Memory\n \n \n Types of Memory\n \n Maximum Inner Product Search (MIPS)\n \n \n Component Three: Tool Use\n \n Case Studies\n \n \n Scientific Discovery Agent\n \n Generative Agents Simulation\n \n Proof-of-Concept Examples\n \n \n Challenges\n \n Citation\n \n References\n\n(3) Task execution: Expert models execute on the specific tasks and log results.\nInstruction:\n\nWith the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path.",
"name": "blog_post_retriever",
"additional_kwargs": {},
"response_metadata": {},
"tool_call_id": "call_3tSaOZ3xdKY4miIJdvBMR80V"
}
]
}
}
----
{
agent: {
messages: [
AIMessage {
"id": "chatcmpl-AB7y9tpoTvM3lsrhoxCWkkerk9fb2",
"content": "Task decomposition is a methodology used to break down complex tasks into smaller, more manageable steps. Here’s an overview of various approaches to task decomposition:\n\n1. **Chain of Thought (CoT)**: This technique prompts a model to \"think step by step,\" which aids in transforming big tasks into multiple smaller tasks. This method enhances the model’s performance on complex tasks by making the problem more manageable and interpretable.\n\n2. **Tree of Thoughts (ToT)**: An extension of Chain of Thought, this approach explores multiple reasoning possibilities at each step, effectively creating a tree structure. The search process can be carried out using Breadth-First Search (BFS) or Depth-First Search (DFS), with each state evaluated by either a classifier or a majority vote.\n\n3. **Simple Prompting**: Involves straightforward instructions to decompose a task, such as starting with \"Steps for XYZ. 1.\" or asking \"What are the subgoals for achieving XYZ?\". This can also include task-specific instructions like \"Write a story outline\" for writing a novel.\n\n4. **LLM+P**: Combines Large Language Models (LLMs) with an external classical planner. The problem is translated into a Planning Domain Definition Language (PDDL) format, an external planner generates a plan, and then the plan is translated back into natural language. This approach highlights a synergy between modern AI techniques and traditional planning strategies.\n\nThese approaches allow complex problems to be approached and solved more efficiently by focusing on manageable sub-tasks.",
"additional_kwargs": {},
"response_metadata": {
"tokenUsage": {
"completionTokens": 311,
"promptTokens": 755,
"totalTokens": 1066
},
"finish_reason": "stop",
"system_fingerprint": "fp_52a7f40b0b"
},
"tool_calls": [],
"invalid_tool_calls": [],
"usage_metadata": {
"input_tokens": 755,
"output_tokens": 311,
"total_tokens": 1066
}
}
]
}
}
----
在上面的例子中,代理并没有将我们的查询逐字插入到工具中,而是去除了诸如”what”和”is”这样的不必要的词语。
同样的原理使得代理在必要时可以利用对话的上下文:
const query3 =
"What according to the blog post are common ways of doing it? redo the search";
for await (const s of await agentExecutor2.stream(
{ messages: [{ role: "user", content: query3 }] },
config3
)) {
console.log(s);
console.log("----");
}
{
agent: {
messages: [
AIMessage {
"id": "chatcmpl-AB7yDE4rCOXTPZ3595GknUgVzASmt",
"content": "",
"additional_kwargs": {
"tool_calls": [
{
"id": "call_cWnDZq2aloVtMB4KjZlTxHmZ",
"type": "function",
"function": "[Object]"
}
]
},
"response_metadata": {
"tokenUsage": {
"completionTokens": 21,
"promptTokens": 1089,
"totalTokens": 1110
},
"finish_reason": "tool_calls",
"system_fingerprint": "fp_52a7f40b0b"
},
"tool_calls": [
{
"name": "blog_post_retriever",
"args": {
"query": "common ways of task decomposition"
},
"type": "tool_call",
"id": "call_cWnDZq2aloVtMB4KjZlTxHmZ"
}
],
"invalid_tool_calls": [],
"usage_metadata": {
"input_tokens": 1089,
"output_tokens": 21,
"total_tokens": 1110
}
}
]
}
}
----
{
tools: {
messages: [
ToolMessage {
"content": "Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\nTree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\n\nTask decomposition can be done (1) by LLM with simple prompting like \"Steps for XYZ.\\n1.\", \"What are the subgoals for achieving XYZ?\", (2) by using task-specific instructions; e.g. \"Write a story outline.\" for writing a novel, or (3) with human inputs.\nAnother quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain Definition Language (PDDL) as an intermediate interface to describe the planning problem. In this process, LLM (1) translates the problem into “Problem PDDL”, then (2) requests a classical planner to generate a PDDL plan based on an existing “Domain PDDL”, and finally (3) translates the PDDL plan back into natural language. Essentially, the planning step is outsourced to an external tool, assuming the availability of domain-specific PDDL and a suitable planner which is common in certain robotic setups but not in many other domains.\nSelf-Reflection#\n\nAgent System Overview\n \n Component One: Planning\n \n \n Task Decomposition\n \n Self-Reflection\n \n \n Component Two: Memory\n \n \n Types of Memory\n \n Maximum Inner Product Search (MIPS)\n \n \n Component Three: Tool Use\n \n Case Studies\n \n \n Scientific Discovery Agent\n \n Generative Agents Simulation\n \n Proof-of-Concept Examples\n \n \n Challenges\n \n Citation\n \n References\n\nResources:\n1. Internet access for searches and information gathering.\n2. Long Term memory management.\n3. GPT-3.5 powered Agents for delegation of simple tasks.\n4. File output.\n\nPerformance Evaluation:\n1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n2. Constructively self-criticize your big-picture behavior constantly.\n3. Reflect on past decisions and strategies to refine your approach.\n4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.",
"name": "blog_post_retriever",
"additional_kwargs": {},
"response_metadata": {},
"tool_call_id": "call_cWnDZq2aloVtMB4KjZlTxHmZ"
}
]
}
}
----
{
agent: {
messages: [
AIMessage {
"id": "chatcmpl-AB7yGASxz0Z0g2jiCxwx4gYHYJTi4",
"content": "According to the blog post, there are several common methods of task decomposition:\n\n1. **Simple Prompting by LLMs**: This involves straightforward instructions to decompose a task. Examples include:\n - \"Steps for XYZ. 1.\"\n - \"What are the subgoals for achieving XYZ?\"\n - Task-specific instructions like \"Write a story outline\" for writing a novel.\n\n2. **Human Inputs**: Decomposition can be guided by human insights and instructions.\n\n3. **Chain of Thought (CoT)**: This technique prompts a model to think step-by-step, enabling it to break down complex tasks into smaller, more manageable tasks. CoT has become a standard method to enhance model performance on intricate tasks.\n\n4. **Tree of Thoughts (ToT)**: An extension of CoT, this approach decomposes the problem into multiple thought steps and generates several thoughts per step, forming a tree structure. The search process can be performed using Breadth-First Search (BFS) or Depth-First Search (DFS), with each state evaluated by a classifier or through a majority vote.\n\n5. **LLM+P (Large Language Model plus Planner)**: This method integrates LLMs with an external classical planner. It involves:\n - Translating the problem into “Problem PDDL” (Planning Domain Definition Language).\n - Using an external planner to generate a PDDL plan based on an existing “Domain PDDL”.\n - Translating the PDDL plan back into natural language.\n \nBy utilizing these methods, tasks can be effectively decomposed into more manageable parts, allowing for more efficient problem-solving and planning.",
"additional_kwargs": {},
"response_metadata": {
"tokenUsage": {
"completionTokens": 334,
"promptTokens": 1746,
"totalTokens": 2080
},
"finish_reason": "stop",
"system_fingerprint": "fp_52a7f40b0b"
},
"tool_calls": [],
"invalid_tool_calls": [],
"usage_metadata": {
"input_tokens": 1746,
"output_tokens": 334,
"total_tokens": 2080
}
}
]
}
}
----
请注意,智能体能够推断出我们查询中的“it”指的是“任务分解”,并因此生成了一个合理的搜索查询——在本例中是“常见的任务分解方法”。
将它们整合在一起
为方便起见,我们将所有必要步骤整合到一个代码单元格中:
import { createRetrieverTool } from "langchain/tools/retriever";
import { createReactAgent } from "@langchain/langgraph/prebuilt";
import { MemorySaver } from "@langchain/langgraph";
import { ChatOpenAI } from "@langchain/openai";
import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { OpenAIEmbeddings } from "@langchain/openai";
const llm3 = new ChatOpenAI({ model: "gpt-4o" });
const loader3 = new CheerioWebBaseLoader(
"https://lilianweng.github.io/posts/2023-06-23-agent/"
);
const docs3 = await loader3.load();
const textSplitter3 = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const splits3 = await textSplitter3.splitDocuments(docs3);
const vectorStore3 = await MemoryVectorStore.fromDocuments(
splits3,
new OpenAIEmbeddings()
);
// Retrieve and generate using the relevant snippets of the blog.
const retriever3 = vectorStore3.asRetriever();
const tool2 = createRetrieverTool(retriever3, {
name: "blog_post_retriever",
description:
"Searches and returns excerpts from the Autonomous Agents blog post.",
});
const tools2 = [tool2];
const memory4 = new MemorySaver();
const agentExecutor3 = createReactAgent({
llm: llm3,
tools: tools2,
checkpointSaver: memory4,
});
下一步
我们已经介绍了构建基本对话式问答应用程序的步骤:
- 我们使用链(chains)构建了一个可预测的应用程序,该程序为每个用户输入生成搜索查询;
- 我们使用代理(agents)构建了一个应用程序,该应用程序会“决定”何时以及如何生成搜索查询。
如需探索不同类型的检索器(retrievers)和检索策略,请访问指南中的 检索器 部分。
如需详细了解 LangChain 的对话记忆抽象功能,请访问 如何添加消息历史记录(记忆) LCEL 页面。